I recently developed a model for a client in which the goal was to identify at-risk customers with chronic conditions to target for outreach in a health coaching program. By targeting the customer for outreach, we hoped to improve the patient’s health, medication adherence, and avoid costly emergency room visits and inpatient admissions. In order to explain how effective the model was, I used a cumulative lift chart created in SAS Enterprise Miner (click the image below to enlarge):
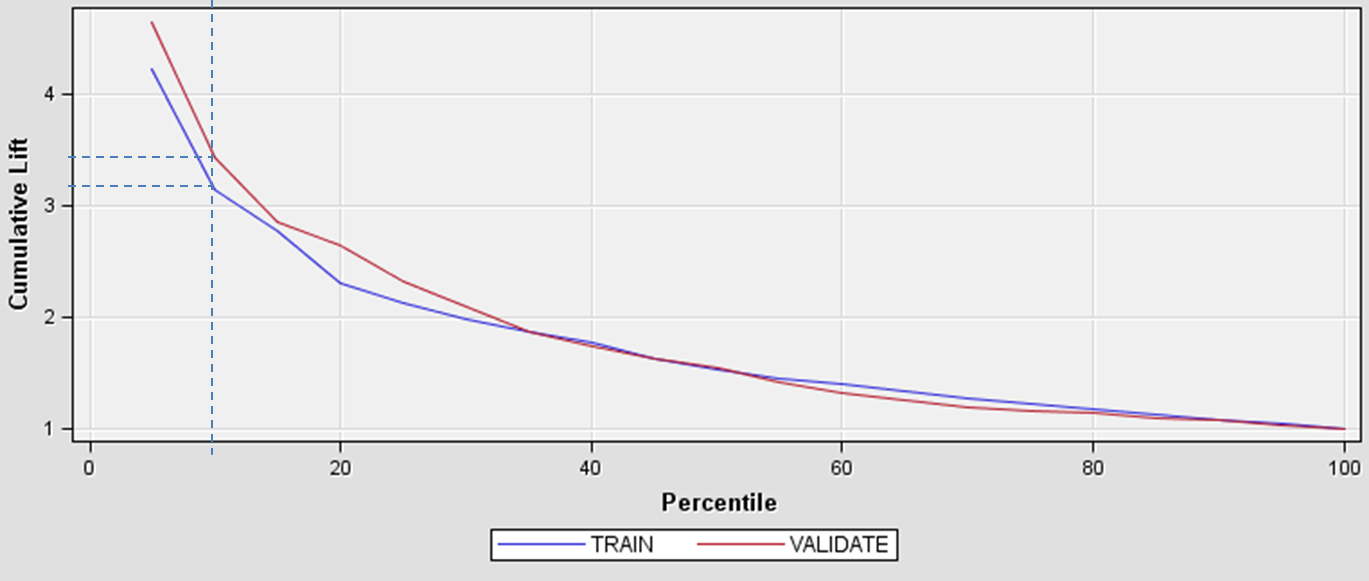
The x-axis shows the percentile and the y-axis shows lift. Keep in mind that the default (no model), is a horizontal line intersecting the y-axis at 1. If we contact a random 10% of the population using no model, we should get 10% of the at-risk customers by default; this is what we mean by no lift (or lift=1). The chart above shows that using the given model we should be able to capture 32-34% of the at-risk customers for intervention if we contact the customers with risk scores in the top 10 percentile (shown by the dashed line). That is more than 3 times as many as if we use no model, so that is our “lift” over the baseline. Here is another example using te same chart: we can move to the right on the lift curve and contact the top 20% of our customers, and we would end up with a lift of about 2.5. This means that by using the model, we could capture about 50% of the at-risk customers if we contact just 20% of them.
The cumulative lift chart visually shows the advantage of using a predictive model to choose who to outreach by answering the question of how much more likely we are to reach those at risk than if we contact a random sample of customers.