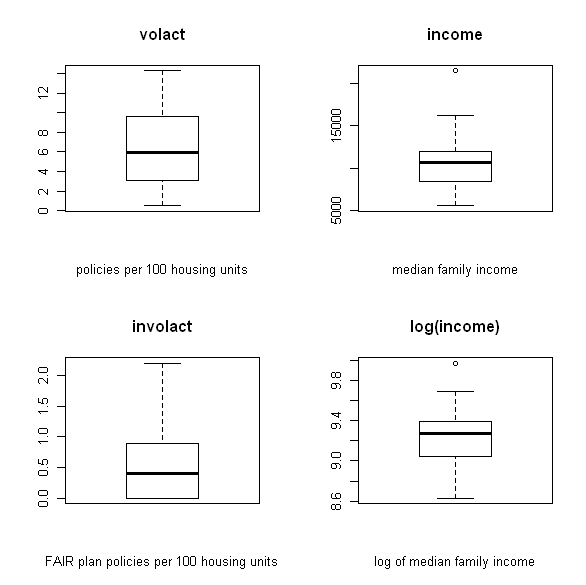
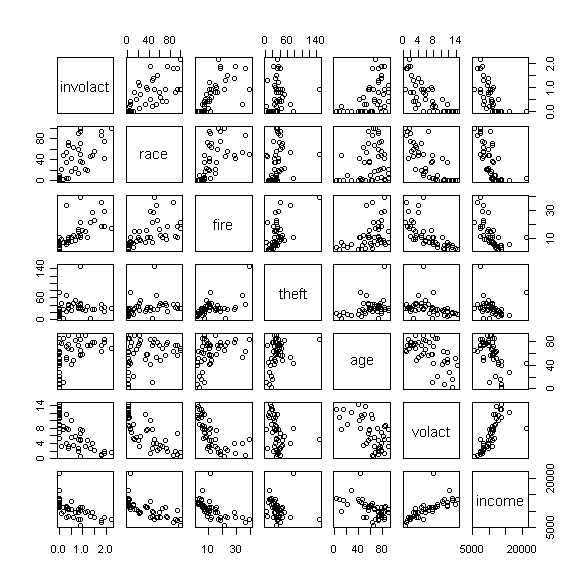
I like to use R when I need to create a correlation matrix and scatter plot for a large number of variables. For example, this is what I want to create for a data set with insurance variables (click images to enlarge):
Figure 1. Correlation matrix of insurance variables

Figure 2. Scatterplot matrix of insurance variables
Here are the steps I use to create the output shown above:
1. First I need to read in my text file, which contains a header row and 8 columns:
cir<-read.table(“CIR.txt”,header=TRUE)
2. Then I make a couple of changes to the file before I run the correlation matrix and create the scatter plot. I keep columns two through five the same (skipping the first column), but I rename the seventh variable to “involact” and modify income (column eight) so that it is calculated in the thousands:
cir<-data.frame(cir[,2:5],involact=cir[,7],income=cir[,8]/1000)
3. Next I create the correlation matrix and the scatterplot, but I round the numbers to three decimal places to make the output more readable for the correlation matrix. To create the scatterplot, I specify that I want to show the relationships with the target variable involact , and then I list the names of the other variables I want to show:
round(cor(cir),3)
pairs(involact~race+fire+theft+age+volact+income, data=cir)